
México
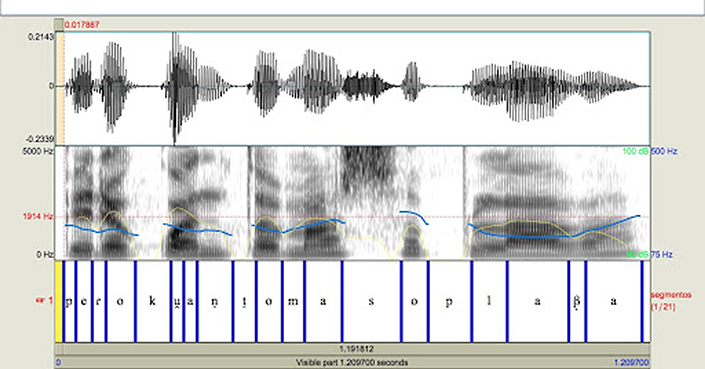
▶ Podrían reconocer a delincuentes por sus voces con investigación forense y lingüística


DeportesHace 2 horas
México derrotó a Canadá, pero no fue suficiente

San Luis PotosíHace 2 horas
Ofrecen programan de titulación gratuita a jóvenes potosinos

San Luis PotosíHace 2 horas
Atienden petición de orquesta sinfónica infantil de Ciudad Fernández

SeguridadHace 4 horas
Dos accidentes en motocicleta dejan a cuatro personas con lesiones leves en Ciudad Valles

San Luis PotosíHace 4 horas
Inician con el programa de bacheo en Aquismón

San Luis PotosíHace 5 horas
Secretaría del Trabajo y Previsión Social fortalece capacitación laboral

SeguridadHace 2 días
Peatón muere tras ser atropellado y arrastrado en Ciudad Valles; su esposa queda herida

DeportesHace 1 semana
En SLP se celebró el Día Nacional del Auto Antiguo

MéxicoHace 1 semana
La caída del peso mexicano y sus consecuencias: Remesas y aranceles

DeportesHace 1 semana
Más de 10 mil personas disfrutaron de la exhibición de autos antiguos

SeguridadHace 1 semana
Fuerte impacto entre automóvil y taxi en el Libramiento Poniente; solo daños materiales

DeportesHace 1 semana
Preparan escenarios para recibir a la Selección Mexicana de Basquetbol
SeguridadHace 1 semana
Fuerte impacto entre automóvil y taxi en el Libramiento Poniente; solo daños materiales

SeguridadHace 1 semana
Vivienda de la colonia Obrera se ve afectada por incendio

SeguridadHace 1 semana
Tragedia en avenida Universidad: Adulto mayor pierde la vida en atropellamiento

San Luis PotosíHace 2 semanas
Ricardo Gallardo inaugura obra y entrega apoyo alimentario en Charcas

SeguridadHace 2 semanas
Mujer en estado de ebriedad choca contra un local comercial

San Luis PotosíHace 2 semanas
Ricardo Gallardo arranca rehabilitación de camino en Villa de Ramos
-
 SeguridadHace 2 días
SeguridadHace 2 díasPeatón muere tras ser atropellado y arrastrado en Ciudad Valles; su esposa queda herida
-

 San Luis PotosíHace 1 día
San Luis PotosíHace 1 díaSe registra accidente en entrenamiento en el autódromo del Parque Tangamanga II
-

 SeguridadHace 3 días
SeguridadHace 3 díasCapturan a jefe de plaza criminal en Ciudad Valles
-

 San Luis PotosíHace 2 días
San Luis PotosíHace 2 díasImpulsa SECESP la sensibilización de jóvenes en telesecundarias